Strategi implementasi Big Data

Gambar diatas diambil dari http://bigsonata.com
Big Data memang menjadi Hits akhir-akhir ini dan banyak yang memperkiraan Big Data is here to stay artinya ini bukan trend sesaat dan akan terus ada dalam kurun waktu yang relatif lama seperti teknologi mobile.
Dikarenakan biaya implementasi yang relatif masih besar, awalnya hanya perusahaan-perusahaan besar yang mampu mengimplementasikan dan merasakan manfaat dari Big Data. Hampir semua perusahaan Fortune 500 memanfaatkan Big Data. Mereka secara garis besar memanfaatkan Big Data untuk mengolah data yang mereka miliki maupun data eksternal untuk membantu dalam mengambil keputusan-keputusan strategis.
Akhir-akhir ini banyak juga startup teknologi yang menyediakan layanan Big Data untuk perusahaan kecil (small medium enterprise / SME) sehingga perusahaan kecilpun juga bisa mendapatkan manfaat dari Big Data.
Secara umum meskipun kedua jenis perusahaan mulai mengimplementasikan Big Data, ada perbedaan diantara keduanya. Untuk Big Data di perusahaan besar mereka lebih menngimplementasikan Big Data untuk multi fungsi. Dengan implementasi ini analisa baru untuk kepentingan lain bisa dilakukan tanpa harus mengubah infrastruktur yang sudah ada secara signifikan. Umumnya perusahaan besar ini memiliki infrastruktur sendiri untuk Big Datanya atau menyewa infrastruktur untuk menampung Big Data mereka (IaaS) seperti New York Times yang menyewa infrastruktur di Amazon. Hal ini tentu dimungkinkan karena mereka memiliki dana yang besar.
Sementara Big Data yang dimanfaatkan oleh SME kebanyakan sudah sangat spesifik untuk suatu analisis data tertentu. Hal ini karena startup yang menyajikan layanan Big Data memang mentargetkan untuk fungsi tertentu. Contoh startup yang menawarkan layanan Big Data ada Bluefin Labs yang menawarkan data analytics untuk data yng diambil dari Social Media. Bluefin Labs sekarang diakusisi oleh Twitter. SME bisa mendapatkan manfaat dari Big data tidak dengan memiliki infrastruktur sendiri tapi dengan berlangganan service dari startup-startup yang menawarkan layanan spesifik Big Data.
Meskipun Big Data sangat populer saat ini dan banyak perusahaan yang memanfaatkannya ada hal-hal yang harus diperhatikan sebelum menggunakan Big Data. Meskipun banyak teknologi Big Data yang Open Source alias gratisan, tetapi untuk memanfaatkan Big Data membutuhkan biaya yang relatif tidak sedikit terutama untuk perusahaan kecil. Untuk itu sangat penting sebelumnya untuk benar-benar pastikan bahwa Big Data bisa memberikan solusi atas masalah yang Anda miliki. Selain itu, karena namanya saja Big Data, pastikan Anda memiliki akses atas data yang nantinya akan diolah dan dianalisis dengan teknologi Big Data. Kalau data yang Anda miliki tidak terlalu besar / tidak bergiga-bergiga dan bertera-tera bytes, pertumbuhan data yang tidak terlalu cepat serta masih terstruktur. Maka sepertinya bisa dipertimbangkan teknologi OLAP lain yang relatif lebih murah dan lebih mudah untuk digunakan.
Beberapa solusi yang biasanya ditawarkan dengan menggunakan Big Data adalah:
- Social data analysis. Solusi ini sepertinya idola buat startup dikarenakan akses data dari social media, seperti facebook dan twitter, yang relatif mudah didapat. Dengan social data analysis bisa dikembangkan kemungkinan lain seperti untuk sentiment analysis, customer segementation, mengukur efektifitas marketing, dsbnya.
- Historical data analysis. Solusi ini menganalisis data masa lalu yang dimiliki suatu perusahaan. Misalnya data penjualan. Solusi ini berfungsi untuk mencari trend atau kecenderungan data sehingga bisa memberikan gambaran apa yang terjadi dimasa lalu.
- Predicitive analysis. Solusi ini pada umumnya digabungkan dengan solusi historical data analysis. Dari data masa lalu maka dikembangkan kecerdasarn buatan yang bisa memprediksi kejadian dan trend di masa yang akan datang. dengan demikian tindakan antisipasi bisa dilakukan mulai dari sekarang.
Kesimpulan dari tulisan ini adalah ada langkah-langkah yang harus dilakukan sebelum mengimplementasikan Big Data yaitu:
- Pastikan ada masalah yang memang ingin dipecahkan dengan Big Data
- Ada data yang akan dianalisis sehingga memberikan solusi dari masalah Anda
- Ada data analyst dan domain expert yang akan membantu dalam proses implementasi dan pemanfaatan hasil dari Big Data. Bisa saja kedua hal ini diperoleh dari konsultan luar.
- Sesuaikan solusi yang Anda cari dengan kemampuan finansial, apakah ingin membangun infrastruktur sendiri atau memanfaatkan third party yang menyediakan solusi Big Data untuk masalah Anda
- Dari waktu ke waktu revisi proses analisis anda dengan data analis dan domain expert untuk mengatur jika ada perubahan dari data yang Anda miliki yang bisa jadi menarik untuk dianalisis.
Apache Pig dan Apache Hive
Kedua tools ini sebenarnya adalah program yang membantu untuk
membuat program Map Reduce di Hadoop. Map Reduce bisa dibuat dengan
menggunakan bahasa pemrograman pada umumnya misalnya Java lalu
dijalankan di Hadoop. Akan tetapi, langkah ini biasanya melibatkan
berbaris-baris kode dan juga sejumlah proses seperti coding, packaging,
dan menjalankan program Map Reducenya sendiri. Untuk mengatasi
kerepotan-kerepotan itulah kedua tools ini hadir. Dengan menggunakan
salah satu dari tools tersebut Map Reduce bisa dikerjakan dengan
beberapa baris kode yang lebih singkat dari cara konvensional dan bisa
langsung dijalankan karena baik Hive ataupun Pig yang akan berhubungan
langsung dengan Hadoop untuk menjalankannya.

Apache Pig adalah tool yang awalnya dikembangkan dan digunakan oleh Yahoo. Yahoo kemudian merilis Apache Pig untuk Apache sehingga bisa dikembangkan dan digunakan secara luas. Apache Pig lebih cocok digunakan untuk proses ETL (Extract-transform-load). Apache Pig terdiri dari dua jenis komponen. Pig Latin dan Pig Runtime. Pig Latin adalah bahasa yang digunakan di Pig untuk membuat Map Reduce. Pig Latin mengubah syntax low-level dari Map Reduce sehingga menjadi bahasa yang mudah dimengerti. Pig Runtime mengubah dan menjalankan script dari Pig Latin menjadi Map Reduce di Hadoop.
Contoh script Pig adalah
Penyusunan proses menjadi beberapa baris yang mudah dipahami ini adalah kekuatan utama Pig. Sehingga bagi yang tidak mengerti SQL atau teknologi datawarehouse lainnya bisa cepat menguasai Pig.

Apache Hive adalah tool selain Apache Pig untuk membentuk program Map Reduce. Apache Hive pertama kali dikembangkan oleh Facebook untuk melakukan data warehouse pada cluster Hadoop mereka yang sangat banyak. Selanjutnya Hive disumbangkan ke Apache Foundation untuk dikembangkan oleh komunitas open source. Hive lebih ditujukan untuk proses data warehouse diatas HDFS.
Perbedaan mendasar antara Apache Hive dan Apache Pig adalah cara penulisan proses dalam membentuk proses Map Reduce. Kalau pada Apache Pig proses dibagi menjadi beberapa baris yang masing-masing adalah sub proses yang logis dalam memproses dan menganalisis data. Sedangkan pada Apache Hive proses Map Reduce dituliskan dengan gaya yang sangat mirip dengan SQL yang pada umumnya ada di RDBMS.
Contoh Script Hive yang menghitung kemunculan huruf
Seperti terlihat pada script Hive diatas, tampak sekali kemiripan
antara Script Hive dengan SQL. Script Hive diatas terdiri dari tiga
statement yang masing-masing diakhiri dengan semi-colon (;). Bagian
pertama adalah membentuk tabel yang akan menampung semua kata. Bagian
kedua adalah menarik semua kata dari file di HDFS ke dalam tabel.
Sedangkan bagian ketiga adalah SQL query yang bisa dilakukan terhadap
data yang sudah dimasukkan ke tabel. Kita bisa melakukan berbagai query
seperti SQL pada tabel yang sudah kita bentuk sehingga tidak hanya
terbatas pada satu query saja. Output dari query tersebut bisa langsung
ke layar, bisa ke file atau ke sistem eksternal menggunakan tool
tambahan seperti Apache Thrift atau Apache Avro.
Untuk pertanyaan mana yang lebih baik antara Apache Hive dan apache Pig, maka jawabnnya sangat tergantung. Tergantung dari kebutuhan dan dari situasi dan kondisi. Saya pribadi memilih kalau bisa dilakukan oleh Apache Hive akan memilih menggunakan Hive daripada Pig. Karena Hive cukup modular sehingga bisa di gabungkan dengan banyak tool lain seperti Spring, Apache Thrift dan Apache Avro. Pig sepertinya bisa juga untuk integrasi ini cuma saya belum menjumpai contoh yang cukup banyak. In the end, keputusan tetap di tangan Anda.
Sebenarnya ada satu lagi tool untuk membuat Map Reduce bernama Sawzall. Sawzall dikembangkan pertama kali oleh Google. Tetapi sayangnya Sawzall ini masih banyak kekurangan sehingga tidak digunakan secara luas. Contoh kekurangannya adalah tidak ada fungsi aggregator yang mengumpulkan data dari HDFS. Entah memang belum dikembangkan atau bagian itu memang belum di buka oleh Google. Mungkin nanti jika Sawzall sudah cukup mature akan dibahas juga disini.
Apache Pig adalah tool yang awalnya dikembangkan dan digunakan oleh Yahoo. Yahoo kemudian merilis Apache Pig untuk Apache sehingga bisa dikembangkan dan digunakan secara luas. Apache Pig lebih cocok digunakan untuk proses ETL (Extract-transform-load). Apache Pig terdiri dari dua jenis komponen. Pig Latin dan Pig Runtime. Pig Latin adalah bahasa yang digunakan di Pig untuk membuat Map Reduce. Pig Latin mengubah syntax low-level dari Map Reduce sehingga menjadi bahasa yang mudah dimengerti. Pig Runtime mengubah dan menjalankan script dari Pig Latin menjadi Map Reduce di Hadoop.
Contoh script Pig adalah
a = load '/user/hue/word_count_text.txt';
b = foreach a generate flatten(TOKENIZE((chararray)$0)) as word;
c = group b by word;
d = foreach c generate COUNT(b), group;
store d into '/user/hue/pig_wordcount';Penyusunan proses menjadi beberapa baris yang mudah dipahami ini adalah kekuatan utama Pig. Sehingga bagi yang tidak mengerti SQL atau teknologi datawarehouse lainnya bisa cepat menguasai Pig.
Apache Hive adalah tool selain Apache Pig untuk membentuk program Map Reduce. Apache Hive pertama kali dikembangkan oleh Facebook untuk melakukan data warehouse pada cluster Hadoop mereka yang sangat banyak. Selanjutnya Hive disumbangkan ke Apache Foundation untuk dikembangkan oleh komunitas open source. Hive lebih ditujukan untuk proses data warehouse diatas HDFS.
Perbedaan mendasar antara Apache Hive dan Apache Pig adalah cara penulisan proses dalam membentuk proses Map Reduce. Kalau pada Apache Pig proses dibagi menjadi beberapa baris yang masing-masing adalah sub proses yang logis dalam memproses dan menganalisis data. Sedangkan pada Apache Hive proses Map Reduce dituliskan dengan gaya yang sangat mirip dengan SQL yang pada umumnya ada di RDBMS.
Contoh Script Hive yang menghitung kemunculan huruf
CREATE TABLE word_text(word STRING)COMMENT 'This is the word table'ROW FORMAT DELIMITED FIELDS TERMINATED BY ' 'LINES TERMINATED BY '\n';LOAD DATA INPATH 'hdfs:/user/hue/word_count_text.txt' INTO TABLE word_text;SELECT word, count(*) as count FROM word_text GROUP BY word;Untuk pertanyaan mana yang lebih baik antara Apache Hive dan apache Pig, maka jawabnnya sangat tergantung. Tergantung dari kebutuhan dan dari situasi dan kondisi. Saya pribadi memilih kalau bisa dilakukan oleh Apache Hive akan memilih menggunakan Hive daripada Pig. Karena Hive cukup modular sehingga bisa di gabungkan dengan banyak tool lain seperti Spring, Apache Thrift dan Apache Avro. Pig sepertinya bisa juga untuk integrasi ini cuma saya belum menjumpai contoh yang cukup banyak. In the end, keputusan tetap di tangan Anda.
Sebenarnya ada satu lagi tool untuk membuat Map Reduce bernama Sawzall. Sawzall dikembangkan pertama kali oleh Google. Tetapi sayangnya Sawzall ini masih banyak kekurangan sehingga tidak digunakan secara luas. Contoh kekurangannya adalah tidak ada fungsi aggregator yang mengumpulkan data dari HDFS. Entah memang belum dikembangkan atau bagian itu memang belum di buka oleh Google. Mungkin nanti jika Sawzall sudah cukup mature akan dibahas juga disini.
Menutupi Kelemahan Hadoop (latency & streaming)
Setelah tulisan sebelumnya mengulas tentang YARN yang mengatasi
kelemahan di Hadoop 1.x yaitu tidak bisa mengolah data set yang sama
secara paralel/bersamaan. Tulisan kali ini mengulas tentang beberapa
kelemahan Hadoop berikutnya yaitu latency dan streaming data processing.
Latency adalah keterlambatan data untuk diambil dari HDFS, dengan menggunakan Map Reduce, ke level aplikasi misalnya web app. Bagi yang sudah pernah menjalankan map reduce di Hadoop akan merasakan adanya kelambatan dalam mengolah data. Kelambatan ini selain karena sifat map reduce yang berdasarkan batch, juga karena ukuran data yang relatif sangat besar.
Untuk mengatasi masalah ini, ada software lain yang bisa ditambahkan. Lazimnya software ini disebut NoSQL. NoSQL adalah Not Only SQL. software yang termasuk NoSQL kebanyakan adalah software database. Antara lain seperti MySQL, Oracle, SQL Server, Mongo DB, Apache HBase, Apache Cassandra.
Biasanya untuk Hadoop yang dipasangkan BUKAN RDBMS seperti MySQL, Oracle DB atau MS SQL Server. Karena umumnya RDBMS tidak terlalu scalable untuk menghandle data yang sangat besar. Untuk lebih detilnya bisa dilihat mengenai CAP Theorem.
Dua NoSQL yang banyak dipakai adalah Apache HBase dan Apache Cassandra. Kedua database ini adalah column-oriented database yang artinya data di pastisi dari node-nodenya berdasarkan column dan bukan berdasarkan row seperti yang dilakukan di RDBMS. Pengaturan seperti ini mempermudah untuk melakukan analisis. Lebih jauh tentang bisa dibaca di Column-oriented Database.


Selain HBase dan Cassandra ada juga NoSQL lain yang dipakai seperti misalnya Mongo DB. Setiap NoSQL memiliki kelebihan dan kekurangannya masing-masing. MongoDB misalnya memiliki kemampuan geospatial yang lebih baik dibanding NoSQL lain. Sehingga jika kemampuan geospatial sangat dibutuhkan maka MongoDB yang digunakan.
NoSQL yang digunakan di Hadoop bisa mengambil data hasil dari Map Reduce sehingga setiap kali level aplikasi, misal web app, ingin mengambil data secara cepat maka data bisa langsung diambil dari NoSQL tanpa harus melakukan map reduce lagi atau membaca file hasil map reduce. Karena alasan inilah NoSQL menjadi bagian yang tak terpisahkan dari ekosistem Hadoop.
Kelemahan kedua Hadoop adalah dibidang analisis pada streaming data secara realtime. Kelemahan ini banyak dikeluhkan oleh pengguna Hadoop karena data yang masuk secara terus-menerus tidak bisa dianalisis langsung secara realtime karena map reduce berjalan secara batch atau periodik. Contoh kasus ini misalnya dalah menghitung hashtag paling populer / trending dari seluruh tweets yang dibuat di twtitter secara realtime.
Ada tiga software yang saya temukan bisa menutupi kelemahan ini. Ketiga software itu adalah Spring-XD, Apache Storm dan Apache Spark Streaming.


Spring-XD adalah salah satu project dari Spring Pivotal yang melakukan analisis sekaligus menyalurkan data dan hasil tersebut ke beberapa tempat seperti misalnya HDFS, AMQP, HTPP dan sebagainya. Spring-XD bisa digunakan tanpa Hadoop. Spring-XD adalah stream analysis tool yang paling mudah diantara keduanya.
Apache Storm adalah analysis tool yang paling populer diantara keduanya. Storm adalah tool yang dikembangkan oleh Twitter. Meskipun statusnya masih dalam inkubasi dari Apache, Storm adalah yang paling banyak digunakan dibanding lainnya di production level.
Apache Spark Streaming sebenarnya adalah salah satu komponen dari Apache Spark. Apache Spark adalah sebuah software untuk menganalisis data secara realtime. Dan Spark Streaming adalah komponen yang menangani data streaming. Dengan memilih Apache Spark Streaming maka jika nantinya Anda ingin fungsi lains eperti misalnya machine learning, maka semuanya bisa dipenuhi dengan menggunakan Apache Spark.
Latency adalah keterlambatan data untuk diambil dari HDFS, dengan menggunakan Map Reduce, ke level aplikasi misalnya web app. Bagi yang sudah pernah menjalankan map reduce di Hadoop akan merasakan adanya kelambatan dalam mengolah data. Kelambatan ini selain karena sifat map reduce yang berdasarkan batch, juga karena ukuran data yang relatif sangat besar.
Untuk mengatasi masalah ini, ada software lain yang bisa ditambahkan. Lazimnya software ini disebut NoSQL. NoSQL adalah Not Only SQL. software yang termasuk NoSQL kebanyakan adalah software database. Antara lain seperti MySQL, Oracle, SQL Server, Mongo DB, Apache HBase, Apache Cassandra.
Biasanya untuk Hadoop yang dipasangkan BUKAN RDBMS seperti MySQL, Oracle DB atau MS SQL Server. Karena umumnya RDBMS tidak terlalu scalable untuk menghandle data yang sangat besar. Untuk lebih detilnya bisa dilihat mengenai CAP Theorem.
Dua NoSQL yang banyak dipakai adalah Apache HBase dan Apache Cassandra. Kedua database ini adalah column-oriented database yang artinya data di pastisi dari node-nodenya berdasarkan column dan bukan berdasarkan row seperti yang dilakukan di RDBMS. Pengaturan seperti ini mempermudah untuk melakukan analisis. Lebih jauh tentang bisa dibaca di Column-oriented Database.


Selain HBase dan Cassandra ada juga NoSQL lain yang dipakai seperti misalnya Mongo DB. Setiap NoSQL memiliki kelebihan dan kekurangannya masing-masing. MongoDB misalnya memiliki kemampuan geospatial yang lebih baik dibanding NoSQL lain. Sehingga jika kemampuan geospatial sangat dibutuhkan maka MongoDB yang digunakan.
NoSQL yang digunakan di Hadoop bisa mengambil data hasil dari Map Reduce sehingga setiap kali level aplikasi, misal web app, ingin mengambil data secara cepat maka data bisa langsung diambil dari NoSQL tanpa harus melakukan map reduce lagi atau membaca file hasil map reduce. Karena alasan inilah NoSQL menjadi bagian yang tak terpisahkan dari ekosistem Hadoop.
Kelemahan kedua Hadoop adalah dibidang analisis pada streaming data secara realtime. Kelemahan ini banyak dikeluhkan oleh pengguna Hadoop karena data yang masuk secara terus-menerus tidak bisa dianalisis langsung secara realtime karena map reduce berjalan secara batch atau periodik. Contoh kasus ini misalnya dalah menghitung hashtag paling populer / trending dari seluruh tweets yang dibuat di twtitter secara realtime.
Ada tiga software yang saya temukan bisa menutupi kelemahan ini. Ketiga software itu adalah Spring-XD, Apache Storm dan Apache Spark Streaming.


Spring-XD adalah salah satu project dari Spring Pivotal yang melakukan analisis sekaligus menyalurkan data dan hasil tersebut ke beberapa tempat seperti misalnya HDFS, AMQP, HTPP dan sebagainya. Spring-XD bisa digunakan tanpa Hadoop. Spring-XD adalah stream analysis tool yang paling mudah diantara keduanya.
Apache Storm adalah analysis tool yang paling populer diantara keduanya. Storm adalah tool yang dikembangkan oleh Twitter. Meskipun statusnya masih dalam inkubasi dari Apache, Storm adalah yang paling banyak digunakan dibanding lainnya di production level.
Apache Spark Streaming sebenarnya adalah salah satu komponen dari Apache Spark. Apache Spark adalah sebuah software untuk menganalisis data secara realtime. Dan Spark Streaming adalah komponen yang menangani data streaming. Dengan memilih Apache Spark Streaming maka jika nantinya Anda ingin fungsi lains eperti misalnya machine learning, maka semuanya bisa dipenuhi dengan menggunakan Apache Spark.
MapReduce: The Executors (and Apache Hadoop YARN)

Sekarang kita review MapReduce dari sisi program yang menjalankannya / eksekutor. Ada perbedaan antara kesekusi Map Reduce untuk Hadoop versi 1.x dan 2.x. Untuk Hadoop 1.x akan diulas secara singkat saja karena sudah mulai sedikit yang memakai Hadoop 1.x. Kebanyakan sudah memakai Hadoop 2.x karena memang Hadoop versi terbaru ini menawarkan fitur yang jauh lebih bagus.
Untuk Hadoop 1.x, Ada dua komponen penting yang mengekseskusi program map Reduce yang kita buat (baik dengan java berupa jara ataupun dengan menggunakan tool seperti Apache Pig dan Apache Hive):
- Job Tracker. Komponen ini berada pada Name Node. Fungsinya adalah mengatur eksekusi dari Map Reduce. Job Tracker akan mengkoordinasikan ekseskusi dari Map Reduce terhadap seluruh data yang ada di cluster Hadoop. Job Tracker juga yang menjadawalkan eksekusi map Reduce sekaligus mengulang eksekusinya jika eksekusi berikutnya gagal.
- Task Tracker. Komonen ini berada di data node. Komonen ini adalah yang sebenarnya mengeksekusi Map reduce terhadap data yang ada di cluster Hadoop. setelah selesai eksekusi, task Tracker memberi tahu Job Tracker hasil dari eksekusi tersebut, gagal atau berhasil.
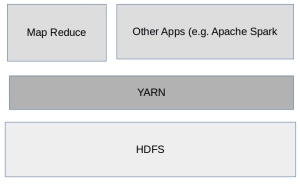
Selanjutnya untuk Hadoop 2.x. Perubahan di versi 2.x adalah jawaban dari banyak kritik untuk Hadoop 1.x, dimana pemrosesan data hanya terjadi dalam batch terhadap data yang sudah ada di cluster. Sehingga tidak bisa untuk pemrosesan untuk data yang masuk secara streaming serta tidak dimungkinkan pemrosesan data yang sama secara bersamaan oleh lebih dari satu aplikasi.
Karena masalah itulah YARN hadir. YARN adalah suatu layer diatas HDFS yang memungkinkan aplikasi lain untuk memproses data yang sama di Hadoop secara paralel dengan Map Reduce. dengan adanya YARN di Hadoop, maka Map Reduce seolah adalah aplikasi lain yang juga melakukan pemrosesan seperti aplikasi lain. Contoh aplikasi lain itu misalnya Apache Spark.
Meskipun ada YARN di Hadoop 2.x tidak ada perbedaan yang signifikan ketika kita menjalankan program Map Reduce di Haoop 1.x ataupun Hadoop 2.x. Hampir semua aplikasi Map Reduce yang bisa jalan di versi 1.x bisa jalan juga di 2.x.
Map Reduce: The Algorithm
Jeroan hadoop berikutnya yang diulas yaitu MapReduce dan YARN.Map Reduce adalah sebuah program. Algoritma sebuah program yang disebut map reduce seperti sebagaimana namanya, prosesnya adalah melakukan map/pemetaan suatu dan reduce/pengurangan atau penggabungan data-data yang sama. Sedangkan detil proses map dan detil proses reducenya tergantung dari data apa yang ingin didapatkan.
Contoh kasus map reduce adalah misalnya jika kita ingin menghitung jumlah penggunaan huruf dalam sebuah buku. Misal kita punya satu file teks besar yang berisi seluruh kalimat yang menyusun sebuah buku. Maka yang dilakukan oleh Map Reduce program yang menghitung penggunaan kata dalam buku tersebut kurang lebih sebagai berikut:
Proses Map:
- Membaca tiap baris kalimat di dalam file teks tersebut.
- Membaca tiap kata yang ada dalam beris tersebut dan membuat sebuah map untuk kata tersebut. Key dari map itu adalah kata tersebut sedangkan value dari map itu adalah 1.
Proses Reduce:
- Melakukan sorting atau pengelompokan map dengan kata-kata yang sama.
- Menjumlahkan untuk mencari total dari kata-kata yang sama tersebut
Contoh program Map Reduce bisa dilihat di bagian examples dari Hadoop yang bisa di download di Apache Hadoop.
Program Map Reduce bisa diciptakan dengan berbagai cara misalnya dengan menggunakan Java atau dengan memakai Tools seperti Apache Hive dan Apache Pig.
Tentang Hadoop Distributed file System (HDFS)

Sekarang kita mulai membedah jeroan dari Hadoop. Seperti ulasan sebelumnya, Inti dari Hadoop itu adalah HDFS dan Map Reduce. Kali ini tulisan adalah mengenai HDFS.
HDFS ini pada dasarnya adalah sebuah tempat atau direktori di komputer dimana data hadoop disimpan. Meskipun direktori ini di “format” supaya bisa bekerja sesuai dengan spesifikasi dari Hadoop.
Meskipun namanya file system, HDFS ini tidak sejajar dengan jenis file system dari sistem operasi misalnya NTFS, FAT32. HDFS ini menumpang diatas file system milik sistem operasi linux atau windows.
Data di Hadoop disimpan di cluster. Cluster biasanya terdiri dari banyak node atau komputer/server. Setiap node di dalam cluster ini harus terinstall Hadoop untuk bisa jalan.
Untuk Hadoop versi pertama (1.x) ada tiga jenis node di dalam cluster:
- Name node: Ini adalah node utama yang mengatur penempatan data di cluster, menerima job dan program untuk melakukan pengolahan dan analisis data e.g. melalui Map Reduce. Name node menyimpan metadata tempat data di cluster dan juga replikasi data tersebut.
- Data Node: Ini adalah node tempat data ditempatkan. Satu block di HDFS/datanode adalah 64 MB. Jadi sebaiknya data yang disimpan di HDFS ukurannya minimal 64 MB untuk memaksimalkan kapasitas penyimpanan di HDFS.
- Secondary name node: Node ini bertugas untuk menyimpan informasi penyimpanan data dan pengolahan data yang ada di name node. Fungsinya adalah kalau name node mati dan diganti dengan name node baru maka name node baru bisa langsung bekerja dengan mengambil data dari secondary name node. Untuk perlu diingat bahwa secondary name node bukan implementasi dari High Availability (bukan backup jika name node mati maka secondary name node otomatis menggantikan).
- Checkpoint Node dan Backup Node. Kedua node ini intinya berfungsi kurang lebih sama dengan secondary name node. Yaitu sebagai backup dari operasi-operasi data dari name node. Checkpoint node melakukan pengecekan setiap interval waktu tertentu dan mengambil data dari Name Node. Dengan check point node maka semua operasi perubahan pada data terekam. Bedanya dengan Secondary name node adalah, secondary name node hanya perlu menyimpan check point terakhir. Backup Node juga berfungsi sama hanya bedanya data perubahan yang disimpan dilakukan di memory bukan di file seperti checkpoint dan secondary node.
Untuk Hadoop versi terakhir (2.x) ada beberapa perubahan di jenis node di cluster untuk mengingkatkan performansinya:
- Lebih dari satu name nodes. Hal ini berfungsi sebagai implementasi dari High Availability. Hanya ada satu name node yang berjalan di cluster (aktif) sedangkan yang lain dalam kondisi pasif. Jika name node yang aktif mati/rusak, maka name node yang pasif langsung menjadi aktif dan mengambil alih tugas sebai name node.
- Secondary name node, checkpoint node dan backup node tidak lagi diperlukan. Meskipun ketiga jenis node tersebut menjadi optional, tetapi kebanyakan tidak lagi ada di cluster yang memakai hadoop versi 2.x. Hal ini karena selain fungsi yang redundan, juga lebih baik mengalokasikan node untuk membuat tambahan name node sehingga tingkat High Availability lebih tinggi.
- Data node tidak ada perubahan yang signifikan di versi hadoop 2.x dari versi sebelumnya.
Setiap data atau file yang disimpan di HDFS selalu memiliki lebih dari satu copy. Ini disebut Refplication Factor (RF). Secara default RF adalah 3. Artinya satu file disimpan di 3 data node sehingga jika ada satu data node yang rusak, maka data node yang lain bisa memberikan filenya. Setiap 3 detik sekali, data node mengirim sinyal, disebut heartbeat, ke name node untuk menunjukkan bahwa data node masih aktif. kalau dalam 10 menit name node tidak menerima heartbeat dari data node, maka data node tersebut dianggap rusak atau tidak berfungsi sehingga setiap request read/write dialihkan ke node lain. Secara umum begini penyimpanan data di name node dan data node.

Kelemahan Hadoop
Meskipun Hadoop sedang benar-benar dipuja akhir-akhir ini sebagai implementasi Big Data paling banyak dipakai, akan tetapi Hadoop juga mempunyai kelemahan. Tidak semua kasus yang berhubungan dengan Big Data bisa ditangani oleh Hadoop. Atau paling tidak bisa ditangani Hadoop dengan baik dan efisien.
Inti dari hadoop adalah HDFS dan Map reduce. HDFS adalah tempat kita menyimpan semua data sedangkan map Reduce adalah process untuk mengolah data tersebut dan mendapatkan informasi yang berguna dari data tersebut.
Kelemahan dari Hadoop yaitu:
- Map reduce hanya bisa berjalan secara serial untuk mengolah data. Artinya tidak bisa dilakukan pemrosesan data secara paralel. Hal ini sangat terasa dengan Hadoop versi 1.X. Untuk Hadoop versi 2.X sudah ada teknologi baru yang ditambahkan yaitu YARN. lebih lengkap akan dibahas di post lainnya.
- Map Reduce hanya bisa berjalan dalam batch atau secara periodik dan tidak bisa terus menerus secara realtime. Hal ini membuat Map Reduce tidak bisa mengolah data dalam bentuk streaming tanpa henti seperti misalnya tweet dari twitter.
Ada apa sebelum Big Data?

Sebelum lebih jauh membahas tentang detil Big Data dan teknologi yang membentuknya, ada baiknya flash back sedikit. Ini untuk memberi penjelasan apa yang melatar belakangi lahirnya Big Data. Hal ini bisa menjadi gambaran masalah apa saja yang bisa diselesaikan dengan Big Data sehingga investasi Big Data yang besar tidak sia-sia.
Data sudah ada sejak jaman manusia ada. Hanya saja bentuknya tidak terstruktur. Bisadiukir dibatu, di tulang dan sebagainya. Jadi seharusnya sebelum Big Data ada, jumlah data yang dimiliki manusia sudah sangat banyak.
Misalnya data di swalayan besar seperti Carrefour pasti sangat banyak. Dalam sehari saja, Carrefour Indonesia mencetak 500.000 struk transaksi. Itu hanya dari transaksi penjualan. Belum lagi data transaksi pembelian dari para supliernya. Belum lagi data karyawan dan seluruh aset-aset Carrefour. Data sebesar ini sudah di miliki, disimpan, diolah dan di analisis Carrefour jauh sebelum teknologi Big Data. Lalu bagaimana perusahaan seperti Carrefour yang memiliki data begitu besar mengolah dan menganalisa datanya kalau teknologi Big Data belum ada?
Banyak teknologi yang sudah ada pada waktu itu untuk mengolah dan menganalisa data. Teknologi itu antara lain OLAP (Online Analitycal Processing) dan OLTP (Online Transactional Processing). Teknologi ini disediakan oleh banyak vendor seperti misalnya Oracle dan Microsoft.
Lalu kalau sudah ada OLAP dan OLTP dari dulu dan sudah dipakai untuk mengolah data yang besar kenapa kita butuh Big Data?
Teknologi yang sudah ada waktu itu punya keterbatasan. Keterbatasan-keterbatasan tersebut antara lain:
- Hanya bisa untuk data terstruktur yang sudah tersimpan di database. Sedangkan data-data lain seperti file teks, excel dsb-nya tidak bisa atau sangat susah diolah dan dianalisa.
- Ukuran data yang diolah juga, meskipun sudah sangat besar, tetap terbatas. Sampai ukuran tera dan exa bytes, proses pengolahan dan analisa data menjadi sangat lambat.
Big Data hadir untuk mengatasi kedua maslah tersebut. Big Data mampu menganalisa semua jenis data baik terstruktur maupun tidak terstruktur. Big Data juga bisa menganalisa data dengan jumlah yang sangat-sangat banyak dan besar. Sehingga data dari waktu-waktu lampau tidak perlu diarsip. Dengan menganalisa semua data yang ada, akan memberi gambaran lengkap tentang apa yang terjadi.
Sign up here with your email
ConversionConversion EmoticonEmoticon